|
Von Graphen, Genen und dem WWW

Online-Skriptum
Bewertung von Webseiten durch Google
Suchmaschinen beginnen
ihre Arbeit damit, spiders auszuschicken, die das World Wide
Web durchforsten, den Inhalt von Webseiten in Datenbanken speichern
und auf ihrem Weg allen Hyperlinks folgen, denen sie begegnen. Ziel
dieser emsigen Tätigkeit ist es, Inhalte und Vernetzungsstruktur
des WWW in einer - mehr oder weniger vollständigen
- "Momentaufnahme" abzubilden und
für die Auswertung von Suchanfragen zu benutzen. Jede Anfrage löst
eine Suche nach Textstellen in den erfassten Daten aus und wird in Form
einer Liste von Treffern beantwortet. Seit den frühen Tagen des
WWW stellt sich dabei die Frage: in welcher Reihenfolge werden die Treffen
dem Anfragesteller präsentiert?
Wie kann bewerkstelligt
werden, dass die Liste der Treffer mit den "relevanten" und
"wichtigen" Webseiten beginnt? Dieses Problem wurde -
in einer für BenutzerInnen befriedigenden Weise -
zuerst von der Suchmaschine Google
gelöst. Die Idee besteht darin, jede erfasste Webseite -
zunächst ganz unabhängig von jeglicher Suchanfrage -
mit einem Bewertungsindex zu versehen, d.h. Webseiten nach ihrer "Wichtigkeit"
zu ordnen. Neben anderen Kriterien (um die es uns hier nicht gehen soll)
ist dieses Ranking die wichtigste Grundlage für die Reihung der
Treffer.
Googles Bewertungsmethode
PageRank wurde im Jahr
1998 von Sergey Brin und Lawrence Page an der Stanford University entwickelt.
Obwohl nicht alle Details offengelegt wurden, ist die Grundidee bekannt.
Ihr wenden wir uns nun zu.
| Das
WWW als gerichteter Graph und der Bewertungsindex |
Ausgangspunkt ist
das WWW als vernetztes System. Es besteht aus elektronischen Dokumenten
(die wir einfach Webseiten nennen), und die Hyperlinks
(kurz: Links), d.h. Verweise auf andere derartige Dokumente enthalten
können. Enthält eine Webseite x
einen Link, der auf die Webseite y
verweist, so sagen wir einfach, dass "x
auf y
verweist". Um die Sache nicht komplizierter als nötig zu machen,
nehmen wir an, dass alle Webseiten bekannt sind und nur statische (von
Benutzer-Eingaben unabhängige) Daten beinhalten. Insbesondere soll
von jeder Webseite x
eindeutig feststehen, auf welche anderen Webseiten sie verweist, und
welche anderen Webseiten auf x
verweisen.
Das ist ein klarer
Fall für einen gerichteten Graphen, dessen Ecken die Webseiten
und dessen (gerichtete, als Pfeile gezeichnete) Kanten die Hyperlinks
darstellen. Die elementaren Beziehungsstrukturen sind:
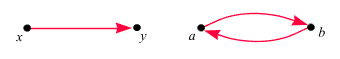 |
x
verweist auf y.
a
verweist auf b,
und b
verweist auf a. |
Gerichtete Kanten
dürfen nicht doppelt vorkommen. (Enthält die Seite x
zwei Links auf y,
so wird das nur einmal gezählt). Ein kleines Spielzeug-WWW sieht
beispielsweise so aus:
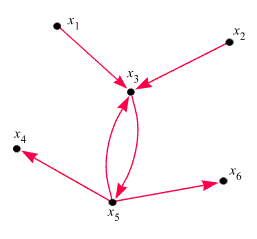
Den Webseiten (Ecken)
haben wir die Namen x1, x2,...x6
gegeben.
Worin könnte
nun ein Bewertungsschema von Webseiten, das lediglich
die durch Hyperlinks definierte Vernetzungsstruktur des WWW ausnutzt,
bestehen? Wie kann festgestellt werden, wie "relevant" eine
Webseite x
ist?
- Klarerweise kann es sich
bei jedem solchen Schema nicht um eine inhaltliche Bewertung
handelt - es geht eher um eine Bewertung
"aus der Sicht der Web-Community", wobei diese "Sicht"
aus der Struktur des WWW (zu einem gegebenen Zeitpunkt) konstruiert
werden soll. Klar ist auch, dass die Zahl der aus x
herausweisenden Links kein gutes Kriterium ist, da diese nur der Sicht
des Anbieters entspricht.
- Folglich ist die Zahl der
Seiten, die auf x
verweisen (einerseits ein Maß für die Betreiber anderer
Seiten, x
ernst zu nehmen, andererseits ein Maß für die Größe
der Website eines Anbieters, die ja auch aus verlinkten Seiten besteht),
der erste Kandidat für eine Bewertung.
- Um Links, die von link farms
(d.h. von Seiten, die lange Listen von Hyperlinks enthalten) kommen,
nicht überzubewerten, ist es angebracht, die Anzahl der Links
auf einer Seite zu berücksichtigen. Eine einfache Gewichtungsvorschrift
ergibt sich, wenn der Bewertungsvorgang als "Wahl" aufgefasst
wird, bei der jede Webseite ihre Stimme für andere Seiten
abgeben kann. Sie tut dies, indem sie ihre Stimme gleichmäßig
auf alle Seiten aufteilt, auf die sie verweist. Der Beitrag, den Seite
x
von Seite y
erhält, ist dann umgekehrt proportional zur Gesamtzahl der Seiten,
auf die y
verweist.
- Weiters ist es sicher sinnvoll,
das Gewicht der Stimme, die eine Seite abgibt, davon abhängig
zu machen, wie "relevant " sie selbst ist.
- Schließlich wird jeder
Seite - gewissermaßen als Bonus dafür,
dass sie überhaupt existiert - ein
fixer Beitrag ganz unabhängig von der Vernetzungsstruktur zugesprochen.
Formalisieren wir
diese Idee. Für jede Webseite x
definieren wir:
- S(x)
bezeichne die Menge aller Webseiten, die auf x
verweisen (die Menge der Ecken, von denen eine Kante auf x
verweist),
- T(x)
bezeichne die Menge aller Webseiten, auf die x
verweist (die Menge der von x
wegweisenden Kanten),
- C(x)
sei die Anzahl der Elemente von T(x)
(die Anzahl der von x
wegweisenden Kanten).
Weiters
bezeichnen wir den Bewertungsindex (englisch: PageRank)
einer Seite x,
den wir im Folgenden definieren wollen, mit R(x).
Die zuvor verbal
formulierte Idee wurde von Brin
und Page in die Form
| R(x) = 1 - d + d |
S
y ÎS(x)
|
|
R(y)
|
. |
| C(y) |
|
(1) |
gegossen. Dabei
ist d
ein "Dämpfungsfaktor", der üblicherweise gleich
0.85
gesetzt wird (in jedem Fall aber größer als 0
und kleiner als 1
sein muss). Wir werden weiter unten
ein paar Worte über ihn sagen. Ist
jeder Webseite ein solcher Bewertungsindex zugeordnet, so werden die
Treffer einer Suchanfrage in der Reihenfolge absteigender Werte
diese Größe präsentiert.
Nehmen wir Formel
(1)
ein bisschen unter die Lupe: Die Summe erstreckt sich über die
Elemente von S(x),
d.h. über alle Seiten, die auf x
verweisen. Jede solche Seite y
liefert einen Beitrag, der proportional zu ihrem "Wert" R(y)
und umgekehrt proportional zur
Anzahl C(y)
der von ihr wegweisenden Links
ist. (Man kann diese Summe auch so betrachten: Jede Seite y
trägt zu anderen Seiten
insgesamt einen Beitrag R(y)
bei, der gleichmäßig
auf alle Seiten, auf die y
verweist, aufgeteilt wird). Zuletzt
wird gewichtet: Der Beitrag zu R(x)
von anderen Seiten (die soeben
besprochene Summe) wird mit d
multipliziert, und ein kostenloser Beitrag, den jede Seite automatisch
bekommt, wird addiert. (Man beachte, dass die Summe der beiden Gewichte
1 - d
und d
gleich 1
ist).
Wir sehen sofort,
dass der Bewertungsindex auch auf der rechten Seite vorkommt -
dort allerdings für die Elemente von S(x).
Handelt es sich also bei (1)
um eine Rekursionsformel? Leider nein, denn wenn x
einen Link auf eine der in S(x)
enthaltenen Seiten enthält, hängt deren Bewertungsindex von
jenem von x
ab, womit R(x)
auch auf der rechten Seite von
(1)
steht. Tatsächlich haben wir es hier mit einem Gleichungssystem
gigantischen Ausmaßes zu tun, denn der Formel (1)
muss genau genommen der Zusatz "für alle x ÎE"
gegeben werden. Jede Webseite x
trägt eine Variable R(x)
bei: Die Anzahl der Variablen
ist gleich der Anzahl aller Webseiten! Dieses Gleichungssystem ist linear-inhomogen,
und kein Computer könnte es in einer angemessenen Zeit exakt lösen.
Allerdings stehen für derartige Gleichungen näherungsweise
Lösungsmethoden zur Verfügung. Bevor wir aber darüber
nachdenken, stellt sich eine viel grundsätzlichere Frage, nämlich,
ob das System überhaupt (und wenn ja, wieviele) Lösungen besitzt!
Exerzieren wir
das zuerst anhand des oben
angegebenen Spielzeug-WWW durch. Es ergeben sich folgende Gleichungen:
| R(x1) |
= |
1 - d |
| R(x2) |
= |
1 - d |
| R(x3) |
= |
1 - d + d (R(x1) + R(x2) + R(x5)/3) |
| R(x4) |
= |
1 - d + d R(x5)/3 |
| R(x5) |
= |
1 - d + d R(x3) |
| R(x6) |
= |
1 - d + d R(x5)/3 |
|
(2) |
Hier widerspiegelt
sich die allgemeine in (1)
definierte Struktur : Jede Seite trägt mit jedem Link zu anderen
Seiten bei. So kommt etwa R(x5)/3
in dieser Eigenschaft 3
mal vor. Wie eine kleine Berechnung ergibt, besitzt das System für
0 < d < 1
genau eine Lösung. Wir geben sie hier wieder für d = 0.85
(auf zwei Stellen gerundet) wieder:
| R(x1) |
= 0.15 |
| R(x2) |
= 0.15 |
| R(x3) |
= 0.59 |
| R(x4) |
= 0.33 |
| R(x5) |
= 0.65 |
| R(x6) |
= 0.33 |
|
(3) |
Seite x5
gewinnt das Rennen, gefolgt von x3.
(Intuitiv hätte man das nicht erwartet, da auf x3 mehr Links
weisen als auf x5).
Stellen wir also nun die Frage, ob die Berechung immer so problemlos funktioniert.
| In
der Sprache der Matrizen |
Das Gleichungssystem
(1)
kann in Matrixform dargestellt werden. Dazu werden die Webseiten, d.h.
die Ecken, in beliebiger Weise durchnummeriert: Wir nennen sie x1, x2,...xn.
Nun kann eine n×n-Matrix
A
(die so genannte Link-Matrix) definiert werden, deren Eintragungen
die Beiträge 1/C(y)
von Gleichung (1)
sind:
| Ajk = |
⎧ |
1/C(xj), |
wenn
xj
auf
xk
verweist |
| ⎨ |
| ⎩ |
0 |
sonst. |
|
(4) |
Insbesondere sind
alle Diagonalelemente von A
gleich 0.
Alle von 0
verschiedenen Eintragungen einer Zeile sind untereinander gleich. Die
Summe der Eintragungen der j-ten
Zeile ist 1,
wenn von xj
zumindest ein Link ausgeht, ansonsten
0. Für
unser obiges Spielzeug-WWW
sieht die Matrix A
so aus:
| A = |
⎛ |
0 |
0 |
1 |
0 |
0 |
0 |
⎞ |
. |
| ⎜ |
0 |
0 |
1 |
0 |
0 |
0 |
⎟ |
| ⎜ |
0 |
0 |
0 |
0 |
1 |
0 |
⎟ |
| ⎜ |
0 |
0 |
0 |
0 |
0 |
0 |
⎟ |
| ⎜ |
0 |
0 |
1/3 |
1/3 |
0 |
1/3 |
⎟ |
| ⎝ |
0 |
0 |
0 |
0 |
0 |
0 |
⎠ |
|
(5) |
Weiters werden
die Bewertungsindizes zu einem n-dimensionalen
Zeilenvektor R = (R(x1), R(x2),...R(xn))
zusammengefasst, und D
bezeichnet den n-dimensionalen
Zeilenvektor, dessen Komponenten alle gleich 1 - d
sind. Gleichung (1)
kann dann in der Form
geschrieben werden,
wobei das Produkt R A
im Sinne der Matrizenmultiplikation
zu bilden ist. Bezeichnet I
die n×n-Einheitsmatrix,
so wird das zu
Ein solches System
besitzt genau dann eine eindeutige Lösung R,
wenn die Matrix I - d A
invertierbar ist. (Die Lösung ist dann klarerweise durch R = D (I - d A)-1
gegeben).
Satz: Ist
0 < d < 1,
so ist die Matrix I - d A
invertierbar.
Beweis:
Sei
0 < d < 1.
Der Trick besteht darin, die Wirkung der Matrix I - d A
auf
Spaltenvektoren
S (deren Komponenten wir mit Sj
bezeichnen) zu untersuchen. Wir müssen zeigen, dass die Gleichung
d A S = S
nur die triviale Lösung S = 0
besitzt (d.h., dass 1
kein Eigenwert von d A
ist). Gemäß der Definition von A
ist die j-te
Komponente des Vektors A S
entweder ein Mittelwert aus Komponenten von S
(wenn xj
auf zumindest eine andere Seite verweist) oder 0
(wenn xj
auf keine andere Seite verweist). Nun wählen wir eine Komponente
Sj,
deren Betrag größer-gleich der Beträge aller anderen
Komponenten von S
ist. Wir nehmen o.B.d.A. an, dass Sj ³ 0
ist (ansonsten betrachten wir -S
anstelle von S).
Die j-te
Gleichung des Systems d A S = S
besagt nun, dass Sj
entweder 0
ist oder d
mal dem Mittelwert einer gewissen Anzahl von Komponenten von S.
Ein solcher Mittelwert kann aber nie größer als das maximale
Element sein, und zudem wird er mit einer positiven Zahl d,
die kleiner als 1
ist, multipliziert. Wäre Sj ¹ 0,
so wäre Sj
gleich einer Zahl, die kleiner als Sj
ist. Da das offensichtlich
nicht der Fall sein kann, folgt Sj = 0.
Wenn das für die Komponente mit dem größten Betrag
gilt, verschwindet der Betrag aller Komponenten,
woraus folgt: S = 0.
Damit ist gezeigt,
dass das Gleichungssystem (1)
für jede denkbare Struktur des WWW genau eine Lösung besitzt:
Ist d
einmal gewählt, bekommt jede Webseite einen wohldefinierten Bewertungsindex.
Jedes R(x)
hat mindestens den Wert 1 - d,
ist also immer positiv. Nach oben sind die Bewertungsindizes durch die
Größe des Web beschränkt. Übungsaufgaben:
- Zeigen Sie: Der Mittelwert
aller Bewertungsindizes ist immer £ 1,
und er ist gleich 1,
wenn jede Seite auf zumindest eine andere Seite verweist.
- Analysieren Sie die Bewertungsindizes
in einem Modell des Web mit n
Seiten, in dem die einzigen Links darin bestehen, dass die ersten
n - 1
Seiten auf die n-te
Seite verweisen!
- Zum Fall d = 1:
Zeigen Sie, dass die Matrix I - A
nicht invertierbar ist! (Tipp: Geben Sie explizit eine nichttriviale
Lösung für S
an!) Die maximale Zahl linear unabhängiger Lösungen von
(1),
welches ja nun die Form R (I - A) = 0
annimmt, kann
1 oder
höher sein. Geben Sie für beide Fälle ein Beispiel
(Graph und Link-Matrix) an!
| Wozu
der Dämpfungsfaktor d? |
Um die Bewertungsmethode
besser zu verstehen, fragen wir nun, wozu der "Dämpfungsfaktor"
d
in Formel (1)
dient. Wäre die natürliche Wahl nicht d = 1?
Der Zweck der Größe
d
besteht darin, eine Pathologie
zu vermeiden. Angenommen,
eine Webseite x3
hat einen gewissen, von 0
verschiedenen Bewertungsindex. Nun werden zwei Seiten
x1
und x2
hinzugefügt
und folgendermaßen verlinkt:
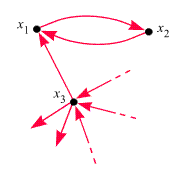
Der Rest des WWW
"hängt" gewssenmaßen an x3
- wir haben ihn hier nur angedeutet. Sehen
wir uns die Sache quantitativ an: Mit (1)
lauten die Gleichungen für R(x1)
und R(x2)
so:
| R(x1) |
= |
1 - d + d (R(x2) + R(x3)/C(x3)) |
| R(x2) |
= |
1 - d + d R(x1) . |
|
(8) |
Was ändert
sich durch die Hinzufügung von x1
und x2
im restlichen Web? Da x3
nun einen wegweisenden Link mehr
besitzt als vorher, wiegt seine Stimme für die Seiten,
auf die es bisher schon verwiesen hat, ein bisschen weniger (C(x3)
ist um 1
gewachsen), aber man würde sich keine dramatischen Änderungen
erwarten. Wird allerdings d = 1
gesetzt, so ergibt sich aus (8)
aber R(x3) = 0,
während R(x1)
und R(x2)
unbestimmt bleiben (hier haben wir einen Fall, in dem das System (1)
für d = 1
zwei linear unabhängige Lösungen besitzt)
und vom Rest des WWW abgekoppelt sind: Der Bewertungsfaktor von x3
ist auf 0
gesunken, ganz egal, wie groß er vorher war! (Die Seiten x1
und x2
fungieren als "Senke"
für den Bewertungsindex, die x3
seine -
bisher vielleicht sehr gute - Position vollständig
wegnimmt). Das ist natürlich nicht wünschenswert. Wird hingegen
ein Wert d < 1
zugelassen, so werden R(x1)
und R(x2)
durch (8)
eindeutig bestimmt:
| R(x1) |
= |
1 + d (1 - d2)-1R(x3)/C(x3) |
| R(x2) |
= |
1 + d2 (1 - d2)-1R(x3)/C(x3) , |
|
(9) |
während der
Wert von R(x3)
durch das Hinzufügen von x1
und x2
nicht berührt wird. Wir
sehen, dass diese Ausdrücke für d = 1
nicht wohldefiniert sind. Ist
d
sehr nahe bei 1,
so bekommen x1
und x2
ungerechtfertigterweise einen
hohen Bewertungsindex. Um ihn ein bisschen zu "dämpfen"
- daher der Name "Dämpfungsfaktor"
-, wird mit Augenmaß ein mittlerer
Wert für d
gewählt.
Weiteres Licht
auf die Bedeutung von d
fällt durch eine andere Interpretation der Größe R(x):
das Modell des Zufalls-Surfers. Ein Web-Surfer startet
mit einer zufällig gewählten Seite und verfolgt (ebenfalls
zufällig) Links auf den Seiten, die er besucht. Die Idee ist
zunächst, dass der Bewertungsindex R(x)
ein Maß
dafür darstellen soll, wie oft der Surfer mit dieser Methode
auf die Seite x
gelangt. Eine
genauere mathematische Analyse von Zufallswegen in gerichteten Graphen
zeigt, dass diese Idee dem Fall d = 1
entspricht.
Wenn nun unser Surfer aber auf x1
gelangt, ist
er gefangen und springt auf ewig zwischen den Seiten x1
und x2
hin und her!
Letztere werden gegenüber allen anderen Seiten, denen ein solches
Einfangen nicht gelingt, einen (unendlich großen) Vorteil haben,
was nicht nur der Idee der Bewertung widerspricht, sondern auch vom
Standpunkt des Wahrscheinlichkeitsbegriffs problematisch ist. Als
Ausweg wird das Modell modifiziert: Von Zeit zu Zeit wird dem Surfer
langweilig, und er sucht sich (zufällig) eine andere Startseite
aus. Dadurch entkommt er Fallen dieses Typs. Der Parameter d
ist ein Maß für die Zahl der Schritte, nach denen eine
neue Startseite gewählt wird. (Im Grenzfall d = 0
verfolgt er gar keine Links, sondern sucht ständig neue Zufallsseiten
auf. Das hat zur Folge, dass alle Seiten den gleichen Bewertungsindex
1
bekommen, da die Wahl mit gleicher Wahrscheinlichkeit auf jede fallen
kann). Die Lösung des Problems ist also eine Schar von Modellen
für das Verhalten fiktiver Surfer, die zu einer Schar von (unterschiedlichen)
Definitionen des Bewertungsindex führt. Aber
Vorsicht: Auch nach dieser Modifikation besitzt das Modell des Zufalls-Surfers
noch einen Haken: Webseiten, von denen kein Link ausgeht.
Das Gleichungssystem
(1)
näherungsweise zu lösen, ist gar nicht so schwierig. Das von
Google verwendete Verfahren ist ein iteratives: Zunächst werden
die erfassten Seiten (in beliebiger Weise) durchnummeriert, und dann
wird Gleichung (1)
der Reihe nach auf die Elemente x,
d.h. die Webseiten angewandt. Wann immer für ein auf der rechten
Seite vorkommendes y
noch kein Bewertungsindex berechnet wurde, wird dieser gleich einem
beliebigen Anfangswert (beispielsweise 1 - d)
gesetzt. Wann immer zuvor ein (Näherungs-)Wert für R(y)
berechnet wurde, wird dieser verwendet. Sind alle Seiten auf diese Weise
behandelt, wird die gesamte Prozedur wiederholt, und nach einer genügend
großen Anzahl von Duchgängen (Google benötigt dafür
etwa 50
und führt die Berechnung in mehreren Stunden durch) ändern
sich die Bewertungsindizes kaum mehr und werden abgespeichert. Von Zeit
zu Zeit werden alle Bewertungsindizes auf den neuesten Stand gebracht.
Für kleine Spielzeug-WWWs ist es nicht schwierig, dieses Verfahren
in Form eines Computerprogramms zu implementieren.
Eine kleine
Modifikation führt Google noch durch. Sie betrifft die so genannten
dangling links, d.h. Links auf Seiten, von denen kein Link
wegweist, und in der Praxis auch Seiten, die von Google noch nicht
erfasst worden sind. Eine Seite y,
die auf keine andere (erfasste) Seite verweist, macht gewissermaßen
von ihrem "Stimmrecht" (im Ausmaß R(y))
keinen Gebrauch. Diese Diskrepanz zwischen "Stimmberechtigten"
und "Wählern" stört die iterative Behandlung von
(1)
eigentlich nicht, aber da Seiten, die noch nicht erfasst wurden, natürlich
nicht in den Algorithmus einbezogen werden können, geht Google
pragmatisch vor: Dangling links werden zunächst entfernt,
und das Verfahren wird ohne sie durchgeführt. (Im obigen
Spielzeug-WWW würde das bedeuten, die Seiten x4
und x6
zu ignorieren).
Ist dann für alle übrig gebliebenen Seiten (von denen zumindest
ein Link ausgeht) ein Näherungswert für den Bewertungsindex
ermittelt, so werden die Seiten ohne ausgehenden Link wieder hinzugefügt.
Um deren Bewertungsindex zu berechnen, wird (1)
direkt (ohne weitere Iteration) angewandt. Den Fehler, den man dabei
macht (ein falscher Wert von C(x)
für jede Seite x,
von der ein dangling link ausgeht) nimmt Google in Kauf.
Wie bereits
erwähnt, hat Google die Details seines Verfahrens nicht offengelegt.
So wird vermutet, dass Seiten, auf die keine andere Seite verweist
(die also nach dem hier besprochenen Schema den Bewertungsindex 1 - d
haben) nicht
angezeigt werden. Weiters werden zur endgültigen Erstellung der
Reihung auch andere Relevanzkriterien (z.B. der Text, der mit einem
Hyperlink verbunden ist) berücksichtigt. Schließlich werden
manche Praktiken, die Bewertung auf unfaire Weise zu steigern, z.B.
das Anlegen (fast) identischer, miteinander verlinkter Seiten, erkannt
und berücksichtigt.
Googles Bewertungskonzept
hat also einen gut durchdachten Hintergrund, und der Erfolg dieser Suchmaschine
zeigt, dass es sich auch in der Praxis bewährt.
Texte der Entwickler
von PageRank:
Auf zahlreichen
Seiten wird diskutiert, wie Websites gestaltet werden müssen, um
möglichst hohen Bewertungsfaktoren zu erzielen. Beispiele:
Zwei Kurzmeldungen
über kommerziell motivierte Manipulationsversuche von PageRank:
|