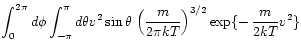By statistics we denote the investigation of regularities
in apparently non-deterministic processes. An important basic quantity
in this context is the ``relative frequency'' of an ``event''.
Let us consider a repeatable experiment - say, the throwing of a
die - which in each instance leads to one of several possible
results - say,
.
Now repeat this experiment times under equal conditions and
register the number of cases in which the specific result occurs;
call this number . The relative frequency of is then
defined as .
Following R. von Mises we denote as the ``probability '' of an
event the expected value of the relative frequency
in the limit of infinitely many experiments:
(1.24)
EXAMPLE:
Game die; 100-1000 trials;
, or
.
Now, this definition does not seem very helpful. It implies that we
have already done some experiments to determine the relative frequency,
and it tells us no more than that we should expect more or less the same
relative frequencies when we go on repeating the trials. What we want,
however, is a recipe for the prediction of .
To obtain such a recipe we have to reduce the event to so-called
``elementary events'' that obey the postulate of
equal a priori probability. Since the probability of any particular
one among possible elementary events is just
, we may then derive the probability of a
compound event by applying the rules
(1.25)
(1.26)
Thus the predictive calculation of probabilities reduces to the
counting of the possible elementary events that make up the event
in question.
EXAMPLE:
The result
is one among
mutually exclusive elementary events with equal a priory probabilities
(). The compound event
consists of the elementary events
;
its probability is thus
.
How might this apply to statistical mechanics? - Let us assume that
we have equivalent mechanical systems with possible states
. A relevant question
is then: what is the probability of a situation in which
(1.27)
EXAMPLE: dice are thrown (or one die times!).
What is the probability that dice each have numbers
of points
? What, in contrast, is the probability
that all dice show a ``one''?
The same example, but with more obviously physical content:
Let gas atoms be contained in a volume , which we imagine
to be divided into equal partial volumes. What is the probability
that at any given time we find particles in each
subvolume? And how probable is the particle distribution
)? (Answer: see below under the heading
``multinomial distribution''.)
We can generally assume that both the number of systems and the
number of accessible states are very large - in the so-called
``thermodynamic limit'' they are actually taken to approach
infinity. This gives rise to certain mathematical simplifications.
Before advancing into the field of physical applications we will
review the fundamental concepts and truths of statistics and
probability theory, focussing on events that take place in number
space, either (real numbers) or (natural numbers).
DISTRIBUTION FUNCTION
Let be a real random variate in the region .
The distribution function
(1.28)
is defined as the probability that some is smaller than the given
value . The function is monotonically increasing and
has and . The distribution function is dimensionless:
.
The most simple example is the equidistribution for which
(1.29)
Another important example, with , , is
the normal distribution
(1.30)
and its generalization, the Gaussian distribution
(1.31)
where the parameters
and define
an ensemble of functions.
DISTRIBUTION DENSITY
The distribution or probability density
is defined by
(1.32)
In other words, is just the differential quotient of the
distribution function:
(1.33)
has a dimension; it is the reciprocal of the dimension of
its argument :
(1.34)
For the equidistribution we have
(1.35)
and for the normal distribution
(1.36)
If is limited to discrete values with a step
one often
writes
(1.37)
for the probability of the event . This
is by definition dimensionless, although it is related to the
distribution density for continuous arguments. The definition
1.37 includes the special case that is restricted to
integer values ; in that case
.
MOMENTS OF A DENSITY
By this we denote the quantities
(1.38)
The first moment
is also called the
expectation value or mean value of the distribution density
, and the second moment
is related to
the variance and the standard deviation:
variance
(standard deviation = square root of variance).
EXAMPLES: .) For an equidistribution
we have
,
and
.
.) For the normal distribution we find
and
.
SOME IMPORTANT DISTRIBUTIONS
Equidistribution: Its great significance stems from the
fact that this distribution is central both to statistical mechanics and
to practical numerics. In the theory of statistical-mechanical systems,
one of the fundamental assumptions is that all states of a system that have
the same energy are equally probable (axiom of equal a priori probability).
And in numerical computing the generation of homogeneously distributed
pseudo-random numbers is relatively easy; to obtain differently distributed
random variates one usually ``processes'' such primary equidistributed
numbers.
Gauss distribution: This distribution pops up everywhere
in the quantifying sciences. The reason for its ubiquity is the
``central value theorem'': Every random variate that can be
expressed as a sum of arbitrarily distributed random variates
will in the limit of many summation terms be Gauss distributed.
For example, when we have a complex measuring procedure in which a
number of individual errors (or uncertainties) add up to a total error,
then this error will be nearly Gauss distributed, regardless of how the
individual contributions may be distributed.
In addition, several other physically relevant distributions, such as
the binomial and multinomial densities (see below), approach the Gauss
distribution under certain - quite common - circumstances.
Figure 1.9:
Equidistribution and normal distribution functions
and densities
Binomial distribution:
This discrete distribution describes the probability that in
independent trials an event that has a single trial probability
will occur exactly times:
(1.39)
For the first two moments of the binomial distribution we have
(not necessarily integer) and
(i.e.
).
Figure 1.10:
Binomial distribution density
APPLICATION:
Fluctuation processes in statistical systems are often described in terms
of of the binomial distribution. For example, consider a particle freely
roaming a volume . The probability to find it at some given time in
a certain partial volume is
. Considering
now independent particles in , the probability of finding just
of them in is given by
(1.40)
The average number of particles in and its standard deviation are
(1.41)
Note that for we have for the variance
,
meaning that the population fluctuations in are then of the
same order of magnitude (namely, ) as the mean number of particles
itself.
For large such that the binomial distribution approaches
a Gauss distribution with mean and variance
(theorem of Moivre-Laplace):
(1.42)
with .
If
and
such that their product
remains finite, the density 1.39 approaches
(1.43)
which goes by the name of Poisson distribution.
An important element in the success story of statistical mechanics is
the fact that with increasing the sharpness of the distribution
1.39 or 1.42 becomes very large. The relative width of
the maximum, i. e.
, decreases as
. For the width of the peak is no more than
of
, and for ``molar'' orders of
particle numbers
the relative width
is already
.
Thus the density approaches a ``delta distribution''. This, however,
renders the calculation of averages particularly simple:
(1.44)
or
(1.45)
Multinomial distribution:
This is a generalization of the binomial distribution
to more than 2 possible results of
a single trial. Let
be the (mutally exclusive)
possible results of an experiment; their probabilities in a single trial
are
, with
.
Now do the experiment times; then
(1.46)
is the probability to have the event just times,
accordingly times, etc.
We get an idea of the significance of this distribution in statistical physics
if we interpret the the possible events as ``states'' that may be
taken on by the particles of a system (or, in another context, by the
systems in an ensemble of many-particle systems).
The above formula then tells us the probability to find among the
particles in state , etc.
EXAMPLE:
A die is cast times. The probability to find each number of points
just times is
(1.47)
To compare, the probabilities of two other cases:
,
. Finally, for the quite
improbable case
we have
Due to its large number of variables () we cannot give a graph
of the multinomial distribution. However, it is easy to derive the
following two important properties:
Approach to a multivariate Gauss distribution: just as the
binomial distribution approaches, for large , a Gauss distribution,
the multinomial density approaches an appropriately generalized
- ``multivariate'' - Gauss distribution.
Increasing sharpness: if and
become very large (multiparticle systems; or ensembles of
elements), the function
has an
extremely sharp maximum for a certain partitioning
, namely
. This particular partitioning
of the particles to the various possible states is then
``almost always'' realized, and all other allotments (or distributions)
occur very rarely and may safely be neglected.
This is the basis of the method of the most probable distribution which
is used with great success in several areas of statistical physics.[2.2]
STIRLING'S FORMULA
For large values of the evaluation of the factorial
is difficult. A handy approximation is Stirling's formula
(1.48)
EXAMPLE: (Near most pocket calculators' limit):
;
.
The same name Stirling's formula is often used for the
logarithm of the factorial:
(1.49)
(The term
may usually be neglected in comparison to
.)
EXAMPLE 1:;
.
EXAMPLE 2:
The die is cast again, but now there are trials. When asked to produce
most pocket calculators will cancel their cooperation. So we
apply Stirling's approximation:
The probability of throwing each number of points just times is
(1.50)
and the probability of the partitioning
is
.
STATISTICAL (IN)DEPENDENCE
Two random variates are statistically mutually independent
(uncorrelated) if the distribution density of the compound probability
(i.e. the probability for the joint occurence of and )
equals the product of the individual densities:
(1.51)
EXAMPLE:
In a fluid or gas the distribution density for a single component of the
particle velocity is given by (Maxwell-Boltzmann)
(1.52)
The degrees of freedom
are statistically independent; therefore
the compound probability is given by
(1.53)
By conditional distribution density
we denote the quantity
(1.54)
(For uncorrelated we have
).
The density of a marginal distribution describes the density
of one of the variables
regardless of the specific value of the other one,
meaning that we integrate the joint density over all possible values
of the second variable:
(1.55)
TRANSFORMATION OF DISTRIBUTION DENSITIES
From 1.32 we can immediately conclude how the density
will transform if we substitute the variable .
Given some bijective mapping
the
conservation of probability requires
(1.56)
(The absolute value appears because we have not required
to be an increasing function.) This leads to
(1.57)
or
(1.58)
Incidentally, this relation is true for any kind of density, such as
mass or spectral densities, and not only for distribution densities.
EXAMPLE 1:
A particle of mass moving in one dimension is assumed to have any
velocity in the range with equal probability; so we have
. The distribution density for the kinetic energy is then
given by
(see Figure 1.11)
(1.59)
in the limits , where
. (The factor
in front of comes from the ambiguity of the mapping
).
Figure 1.11:
Transformation of the distribution density (see Example 1)
EXAMPLE 2:
An object is found with equal probability at any point along a circular periphery;
so we have
for
. Introducing cartesian coordinates
,
we find for the distribution density of the
coordinate , with
, that
Problems equivalent to these examples:
a) A homogeneously blackened glass cylinder - or a semitransparent drinking straw -
held sideways against a light source: absorption as a function of the distance from the axis?
b) Distribution of the -velocity of a particle that can move randomly in two dimension,
keeping its kinetic energy constant.
Simulation 1.6:
Stadium Billiard. Distribution of the velocity component .
[Code: Stadium]
c) Distribution of the velocity of any of two particles arbitrarily moving in one dimension,
keeping only the sum of their kinetic energies constant.
Figure 1.12:
Transformation of the distribution density (see Example 2)
For the joint probability density of several variables the transformation
formula is a direct generalization of
1.58, viz.
(1.61)
Here we write
for the
functional determinant (or Jacobian) of the mapping
,
(1.62)
EXAMPLE 3: Again, let
, and
as in equ. 1.53. Now we write
, with
(1.63)
The Jacobian of the mapping
is
(1.64)
Therefore we have for the density of the modulus of the particle
velocity
, or
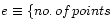
.
is one among
mutually exclusive elementary events with equal a priory probabilities (
). The compound event
consists of the elementary events
; its probability is thus
.
dice are thrown (or one die
times!). What is the probability that
dice each have numbers of points
? What, in contrast, is the probability that all dice show a ``one''?
, which we imagine to be divided into
particles in each subvolume? And how probable is the particle distribution
)? (Answer: see below under the heading ``multinomial distribution''.)
we have
,
and
.
and
.
is
. Considering now
independent particles in
of them in
we have for the variance
, meaning that the population fluctuations in
) as the mean number of particles itself.
,
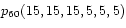
. Finally, for the quite improbable case
we have
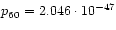
(Near most pocket calculators' limit):
;
.
;
.
trials. When asked to produce
most pocket calculators will cancel their cooperation. So we apply Stirling's approximation:
times is
![\begin{displaymath}
p_{120}(20,\dots,20) = \frac{120!}{(20!)^{6}}
\left( \frac{1...
...ht)^{20} \frac{1}{20!}
\right]^{6}
= 1.350 \cdot 10^{-5} ,
\end{displaymath}](img351.png)
is
.
are statistically independent; therefore the compound probability is given by
moving in one dimension is assumed to have any velocity in the range
with equal probability; so we have
. The distribution density for the kinetic energy is then given by (see Figure 1.11)
, where
. (The factor
in front of
comes from the ambiguity of the mapping
).
for
. Introducing cartesian coordinates
,
we find for the distribution density of the coordinate
, with
, that
Simulation 1.6: Stadium Billiard. Distribution of the velocity component
. [Code: Stadium]
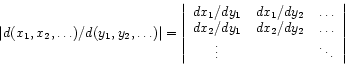
, and
as in equ. 1.53. Now we write
, with
is
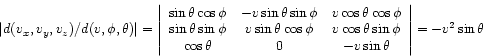
![\begin{figure}\includegraphics[width=180pt]{fig/f1glv.ps}
\includegraphics[width=180pt]{fig/f1nvd.ps}
\end{figure}](img283.png)
![\begin{figure}\includegraphics[width=300pt]{fig/f1bvd.ps}
\end{figure}](img291.png)
![\begin{figure}\includegraphics[width=180pt]{fig/f1tr1.ps}
\includegraphics[width=180pt]{fig/f1tr2.ps}
\end{figure}](img377.png)
![\begin{figure}\includegraphics[width=180pt]{fig/f1tr3.ps}
\includegraphics[width=180pt]{fig/f1tr4.ps}
\end{figure}](img384.png)